NVIDIA-GPU历史
1.概念辨析
1.1 什么是GPU
- GPU(Graphics Processing Unit)即图形处理单元,又称显示核心、图形处理器(有时也统称显卡),最初是一种用来加速图形渲染的专用处理器。
- GPU这一概念是NVIDIA公司在1999年8月发行GeForce 256绘图处理芯片时首先提出的,此前计算机中并不将其看作独立的计算单元。
- GPU的特性在于能够同时处理大量数据(准确说是同时进行大量简单运算工作),这对机器学习、视频剪辑及游戏渲染非常有用。
1.2 GPU与显卡的区别
我们经常会将“GPU”和“显卡”这两个词混用,但实际上二者存在细微差别。
就像主板包含CPU一样,显卡更像是一块包含了GPU的内插板(add-in board)。除了GPU芯片外,它还包含了电路板(PCB)、显存、接口电路、散热器等大量组件。显卡经常被看作一块完成图形计算、图像信号转换传输的独立硬件。在台式机中多通过主板上的PCIE(Peripheral Component Interconnect Express)插槽与计算机其他部分相连。在笔记本中受体积和重量的限制,显卡通常会通过非标准或独特的接口作连接。
直观地说,GPU是图形处理芯片,而显卡则是你购买的最终成品。但在日常讨论中为了简化,这一界限早已被模糊,本文其他部分的讨论中也会默认“显卡即GPU”的指代。
1.3 集成GPU与独立GPU
GPU通常可以看作有两个基本类型,即IGPU(Integrated Graphics Processing Unit)和DGPU(Discrete Graphics Processing Unit),也就是常说的集显(核显)和独显。
独显位于独立的电路板中,通过主板上的PCIE槽与计算机其他部分相连。所谓的“独立”是指该显卡享有专用的内存(即自带显存)。独显的优势在于性能更强、不消耗系统的存储资源、往往拥有一些专用的加速单元(诸如CUDA),但价格、功率、体积都更高(大)。
集显不在独立的电路板上,通常与CPU一起嵌入芯片,也有少部集成在主板上(2009年后罕见)。集显工作时需要借用一部分内存充当显存。集显的优势在于可以使架构更轻薄、功耗更低、设计成本更低,但受限于空间、显存等方面因素,其性能往往较弱。(据Intel统计)市场上绝大部分显卡都是集显,集显也是轻薄本的主力显卡。随着技术的发展,一些集显也有不弱于低端独显的能力。
目前,独显领域是AMD和INVIDIA(英伟达)争锋。PC端的集显主要是Intel的Iris Plus和Intel的UHD;而在移动设备端,则是由Qualcomm(高通)和MediaTek(联发科)生产GPU,这些GPU往往和CPU及其他核心移动芯片组组件位于同一芯片中。
2.GPU与CPU
2.1 GPU的优势
现如今,GPU已经成为计算机中最重要的部件之一,GPU最初设计用来加速3D图形的渲染,但时至今日,GPU已经被赋予了更多可能性。图形程序员可以利用先进的照明和阴影技术来创造更有趣的视觉效果和真实场景,这为视频剪辑制作、游戏效果带来了全新的体验。而其他开发者也开始利用GPU来大幅加速高性能计算、深度学习等。
我们常说GPU是为并行处理而设计的,更准确地说法是:GPU被设计用于图形渲染,更适合完成高计算密度和并行处理场景的任务。这里借用[《NAVIDIA CUDA Programming Guide》](Microsoft Word - CUDA PG 1 1 chs.doc (nvidia.cn))的一幅图:
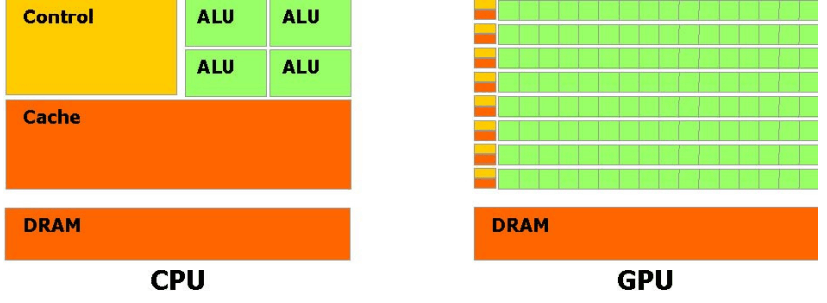
从上图中可以直观地看到,GPU将更多的晶体管投入到了运算单元(ALU),而削弱了控制(Control)和高速缓存(Cache)的能力。这就意味着GPU能同时进行更多简单运算,但在面对需要复杂控制电路配合的运算时则有些捉襟见肘。
以下摘录原书中的两段话(适当调整了措辞断句)
GPU 特别适合于并行数据运算的问题——同一个程序存在许多并行数据元素, 并带有高运算密度(算术运算与内存操作的比例)。由于同一个程序要执行每个数据元素(运算差异小), 降低了对复杂控制的要求; 并且,因为它处理许多数据元素并据有高运算密度,存储访问的延迟也可以被忽略。
并行数据处理,意味着数据元素以并行线程的方式处理。许多处理大量数据(例如数组)的应用程序可以使用一个并行数据的编程模型来加速计算。在3D 渲染上,庞大的像素集和顶点被映射到并行线程中;图像和媒体处理中,例如着色的图像后处理、录像编码和解码、 图像缩放比例、立体视觉以及图像识别也可以映射图像块和像素到并行处理线程中。实际上, 图形领域外的许多算法同样可以通过并行数据处理得到加速,从信号处理、物理模拟到金融计算、生物计算乃至深度学习等。
2.2 CPU的优势
再来看CPU,它拥有强大的算术运算单元,可以在很短的时钟周期内完成算术运算;CPU有更大、层次更多的高速缓存单元,有效降低了数据访存取带来的指令时延;CPU拥有复杂的逻辑控制单元,能够完成更困难的控制和调度任务(诸如分支预测等)。CPU是天然的leader,也能够更快、更精确地处理复杂指令。而GPU则是以大吞吐量为前提,简化了控制和数据缓存,靠“数量”取胜。
2.3 CPU与GPU的分工
笔者很喜欢一个比喻:GPU的运算速度取决于雇了多少小学生,而CPU的运算速度取决于请了多么厉害的教授。一切抛开控制谈算力的讨论,都是“耍流氓”。CPU和GPU没有谁更强,只有不同场景下谁更合适,他们都是基本的计算引擎,彼此分工不同罢了。Intel官网的一篇文章详尽探讨了CPU和GPU的分工,来帮助计算机使用者更好地设计高性能的软件、更好地根据工作类型搭配硬件(原文参考[4]),笔者摘录意译了一部分内容:
2.3.1 cpu和gpu的区别
CPU和GPU有很多共同点,他们都是重要的计算引擎,都是基于硅制造的微处理器,都能处理数据,但GPU和CPU有着不同的架构,是为不同的目的而设计的。
CPU被看作是计算机系统的大脑,它拥有更复杂的控制、存储和计算结构,适用于更广泛的工作任务,特别是存在延迟或更看重单核性能的工作。CPU是一个强大的执行引擎,它将更少的内核集中在单任务和快速处理上,这使得它从串行计算到运行数据库等多方面都具有独特的优势。
GPU则由许多粒度更小、用途更专一的核组成。当一个处理任务可以在许多核心之间进行分割和处理时,这些核心可以通过协同工作提供巨大的性能。最初的GPU是为加速特定3D渲染任务而设计的专用处理器,但现在已经变得更加灵活且具备了更强的可编程性。虽然GPU的主要功能仍然集中在图形处理和为顶级游戏提供更加逼真的视觉效果,但不可否认GPU已经发展为了更通用的并行处理器。
2.3.2 加速深度学习和人工智能
GPU的并行处理和高密度计算优势,使得对于多层神经网络的深度学习模型训练或大量特定数据集(如二维图片)的处理,GPU能提供更理想的加速效果。此外,现在很多深度学习算法都被改编为适用GPU加速的方法。
时过境迁,CPU和其上运行的软件库也发展地更加适用深度学习。例如因特尔至强系列中的Intel Deep Learning Boost,就是通过优化大量的软件库、增加专用的AI硬件来优化深度学习任务的性能。此外,在一些非图像深度学习任务中(诸如:语言类、文本类、时序数据),CPU大放异彩;对于复杂的模型或者深度学习应用(诸如二维图像的检测任务),CPU也能通过提供比GPU大得多的内存来表现出更好的性能。
From CPU vs. GPU to CPU and GPU !
3. NVIDIA GPU系列
目前主要的独显厂家是NVIDIA和AMD,限于篇幅我们将着重介绍NVIDIA的显卡系列。
英伟达的显卡,通常基于微架构设计芯片,根据显卡系列的受众来设计显卡并实装芯片,同一系列当中再进行不同性能等级的硬件定制从而分化出系列型号或档次(尤以GeFore系列为例),在同一型号的同一代中又会通过设计微调来细分性能档次,从而形成了非常严密的系列(性能、价格)递进(也有可能乱序),被显卡用户戏称为“老黄刀法精确”。这样繁杂的划分(调整)之下,通过显卡命名来判定不同显卡间性能的差异变得比较困难。
3.1 GPU微架构
英伟达的第一款GPU架构致敬摄氏温度,此后则多致敬历史上著名的科学家,截至2021年英伟达总共提出了12种微架构,按照时间先后顺序列出其名称、发布时间及命名致敬:
| 架构名 | 发布时间 | 命名致敬 |
|---|---|---|
| Celsius | 1999 | 摄氏度(温度单位) |
| Kelvin | 2001 | 威廉·汤姆森 (开尔文温度提出者) |
| Rankine | 2003 | 兰金(兰氏温度提出者) |
| Curie | 2004 | 居里夫人 |
| Tesla | 2006 | 特斯拉 |
| Fermi | 2010 | 费米 |
| Kepler | 2012 | 开普勒 |
| Maxwell | 2014 | 麦克斯韦 |
| Pascal | 2016 | 帕斯卡 |
| Volta | 2017 | 伏打 |
| Turing | 2018 | 图灵 |
| Ampere | 2020 | 安培 |
微架构(MicroArchitecture)指的是处理器的设计方式(设计思想),可以具体到处理器簇中有多少core、是否包含L1或L2缓存、是否有双精度计算单元等等。
3.2 GPU芯片
英伟达的显卡芯片命名规则为:G(GPU) + X(芯片所用架构名的首字母) + 数字(表示型号)。例如:GT200,表示基于Tesla架构设计的200代(型)芯片。同一架构的芯片设计思路相同,但在细节上会有改变,例如:GK210比GK110的寄存器数目多一倍。
3.3 显卡系列
英伟达将旗下设计的显卡分为三类:GeFore系列(用于家庭娱乐)、Quadro系列(用于工作站)、Tesla系列(用于服务器)。
对于Tesla系列而言,其没有显示输出接口,仅仅专注于数据计算,主要类型:
- K型卡:专注于高性能科学计算,比较突出的优点是具有较高的双精度浮点运算能力,并且支持ECC内存。
- M型卡:专门用于深度学习网络训练的显卡。
对于GeFore系列而言,有图形输出接口。
- (仅供了解 不要抬杠)从历史角度来看,GPU的类型(型号)是不同硬件的定制,可以理解为不同性能规格(主要体现在时钟频率和显存的增强):G/GS(入门) < GT(普通) < GTS(中端) < GTX(高端)。笔者只希望读者了解这段历史,但并不希望读者套用到当下环境中。
- 随着时间推移,GeFore型号名开始变成了粗分显卡性能的前缀词,当下这个前缀词更是成为了显卡性能或技术的时代标志,例如目前最新的RTX系列,就是因为引入光线追踪技术(Ray Tracing)而得名。它与GTX不能再看作同时代产品的不同硬件定制,而是GeFore系列下不同技术时代的产品,RTX系列表示的是GeFore显卡最新技术和更高性能天花板的产物。
3.4 GeForce显卡命名规则
以GeForce GTX 1660 Ti为例,英伟达推出的GeForce显卡一般遵循如下命名规则:
GeForce(显卡系列) GTX(显卡前缀) 16(系列编号或称代数) 6(显卡性能档次定位) 0(末尾数字一般为0 用来补位) Ti(后缀)
其中要注意:
- 代数:英伟达GeForce显卡的代数(系列编号)很不规整,详情参考1.6.5。
- 后缀:没有后缀是正常版、SE后缀是削弱版、Ti后缀是加强版( 一般加Ti的比正常版频率提高30%左右 有测试者称 实际性能提升约20%) 、M后缀一般是笔记本电脑专用等,后缀还有LE、super、pro等,会根据市场情况不定时增减,日常关注有无Ti即可。
- 特别的,当命名中存在MX或M字样时,表示该显卡是用在笔记本端的。
3.5 GeForce系列(完整版)
思前想后,笔者还是决定专开一栏对GeForce不同代的命名差异做一下整理,下面主要介绍Desktop GPU的GeForce series及他们的一些特点。
GeForce 256:是GPU的开山鼻祖,首次使用Celsius 微架构,始发于1999年,有GeForce 256 SDR和GeForce 256 DDR两款。
GeForce2系列:这一系列开始划分出多种型号,始发是2000年的GeForce2 GTS。
GeForce3系列:2001年发布的GeForce,首次使用Kelvin架构,是全球第一款支持DX8(Direct3D 8.0)的显卡,游戏福音。
GeForce4系列:2002年发布的GeForce4 Ti 4200,支持高效抗锯齿技术(Accuview Antialiasing),更好的图形显示(游戏画面)效果。是NVIDIA历史上性价比最高的卡。
GeForce FX系列:首次使用Rankine架构,采用了更成熟的DDR显存,支持DX9技术,并在多方面做了优化改进,标志英伟达真正意义上的高端显卡出现,首发2003年。
GeForce6系列:首次使用Curie架构,除了性能巨大提升,还创造出基于PCIE的SLI(Scalable Link Interface)模式,在一块支持双PCIE接口的主板上可以同时使用两块同型号的PCIE显卡,首发2004年。
GeForce7系列:2005年首发的GTX 7800GT,是首款消费级的双芯显卡,GTX入场。
GeForce8系列:2007年首发,是首款使用Tesla微架构芯片的显卡,引入了CUDA。
GeForce9系列:2008年首发的GeForce 9600GT,对8系列作了完美改进,提高性能降低功耗。也是GeForceX系列的最后荣光。
GeForce 100系列:2009年首发,并且开始使用GeForce G/GT/GTS来代表不同级别。
GeForce 200系列:2009年首发的GTX 280,正式开启了全新的GeForce GTX 200系列,该系列显卡拥有图形处理和并行计算结构体系。
GeForce 300系列:2009年11月首发GeForce 310,本系列没有GTX,支持了DX10。
GeForce 400系列:2010年首发的GEForce GTX 480,首次支持Fermi架构。
GeFroce 500系列:2011年首发的GTX 580中采用完整的Fermi核心(512个流处理器)。
GeForce 600系列:2012年首发GTX680,采用全新的Kepler架构和台积电28nm工艺,英伟达显卡突破性地加入了动态加速,年底发布了更强悍的GTX690。
GeForce 700系列:2013年首发了GTX TITAN、GTX780Ti,由于第一代Kepler架构表现良好,英伟达推出了大核心芯片GK110,并将实装该芯片的显卡命名为TITAN系列,这是首次没采用数字编号命名显卡,也是N卡家族中第一代TITAN,至此TITAN成为了N卡中至强的代表,官网驱动下载页甚至将TITAN看作了与GeFroce并列的系列。
GeForce 800系列:抱歉,没有这个系列,又又又跳卡了。
GeForce 900系列:2014年首发的GTX 980和GTX 970,采用了全新的Maxwell架构。
GeForce 10系列:2016年发布了GTX1080(旗舰)、GTX 1070(高端)、GTX1060(中高端),采用了全新的Pascal架构,并且工艺达到了16nm,晶体管数量暴增,核心频率大幅提升,超频轻松突破2GHz,带来了GDDR5X显存、异步运算改进、新的VR技术等。在2017年发布的GTX1080 Ti更是顶配的Pascal架构显卡,超越了当时最强卡皇TITAN X,成为了GTX时代的神话卡。
GeForce 20系列(RTX20):2018年首发的GeForce RTX2080Ti、RTX2070、RTX2060,不仅采用了全新的Turing架构,并且引入了光线追踪技术,也正式宣告了GTX时代的落幕,20之后再无GTX,RTX代替GTX成为显卡市场主力军。同年12月,英伟达发布了RTX中的第一块TITAN霸主,全称Nvidia TITAN RTX。
GeForce 16系列:2019年发布了GTX 1650、GTX1650Spuer、1660、1660Super、1660Ti,GeForce 16系列是GTX最后的荣光,是GeForce 20系列的阉割版本,相比10系列提升并不大,但使用的是下一代架构Turing。
GeForce 30系列(RTX30):
- 2020年发布的RTX 3090、RTX 3080、RTX3070,采用了全新的Ampere架构,相比RTX20的Turing架构是革命性提升,Ampere集成了第二代RT光线追踪核心、第三代Tensor张量核心。其中的旗舰卡RTX3090搭载了24GB的GDDR6X显存,拥有10496个流处理器,在游戏和深度学习方面带来了前所未有的体验。
- 2021年为了调节挖矿对显卡市场的冲击,发布了”锁矿”的RTX 3060,实际效果欠佳,后又删除。
- 2021年,为了弥补RTX3090和RTX3080之间的性能差距,于6月份发布了RTX 3080 Ti 和RTX 3070 Ti。
3.6 显卡天梯图
更多显卡性能的比较,可以搜索2021显卡天梯图 或 gpu hierarchy 2021,下面pull一张来自 百度贴吧秋刀鱼半藏 大佬更新于2021年11月的显卡天梯图。

- 图形处理器 - 维基百科,自由的百科全书 (wikipedia.org) ↩
- What Is a GPU? Graphics Processing Units Defined (intel.com) ↩
- GPU vs Graphics Card Simple Guide] - GamingScan ↩
- CPU vs. GPU: What’s the Difference? (intel.com) ↩
- 【GPU编程系列之一】从深度学习选择什么样的gpu来谈谈gpu的硬件架构 | 听见下雨的声音 (chenrudan.github.io) ↩
- List of Nvidia graphics processing units - Wikipedia ↩
- NVIDIA GPU 架构梳理 - 知乎 (zhihu.com) ↩
- 快速回顾NVIDIA显卡发展史,看看小伙伴们都用过哪些显卡。_GeForce (sohu.com) ↩
- 《史上最全桌面级显卡天梯图》专用更新帖(公测版)_amd吧 ↩